Personalized Video Generation
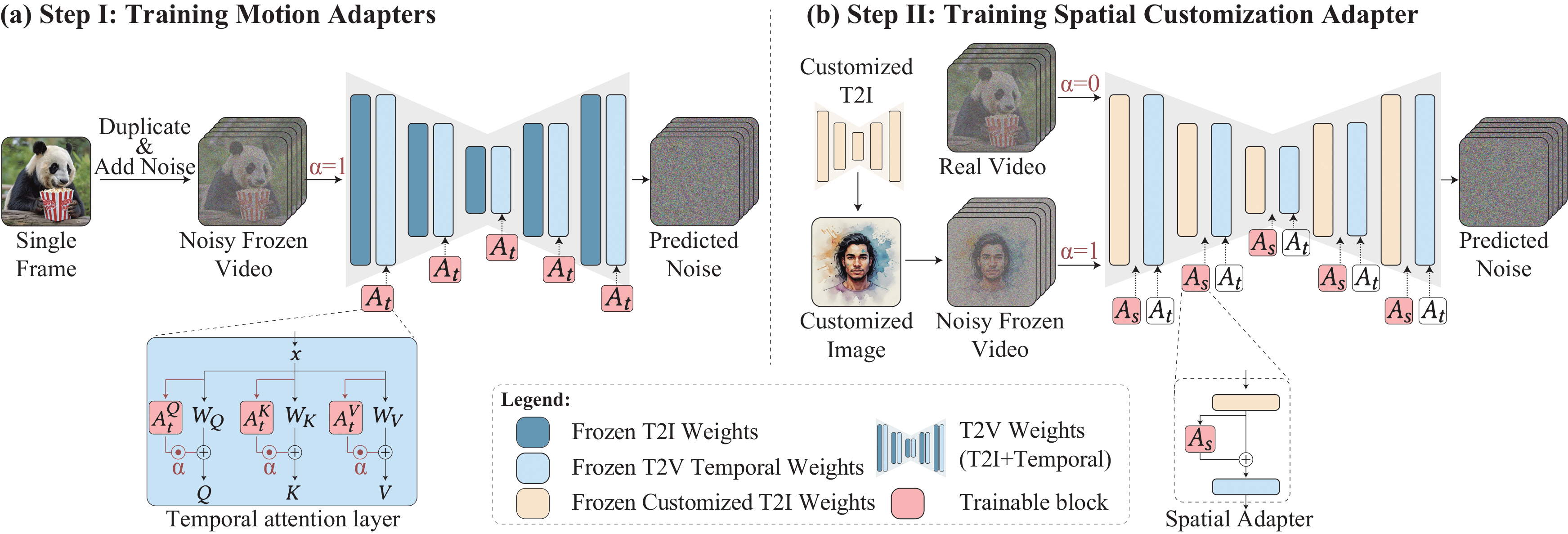
Given a text-to-video (T2V) model built over a text-to-image (T2I) model, Still-Moving can adjust any customized T2I weights to align with the T2V model. This adaptation uses only a few still reference images, and preserves the motion prior of the T2V model.
Below we show examples of personalized video generation by adapting personalized T2I models (e.g. DreamBooth, [Ruiz et al. 2022]).
* Hover over the video to see the prompt.
Reference images
Generated Personalized Videos

[V] chipmunk flying with a cape
[V] chipmunk riding a skateboard
[V] chipmunk picnicking under a tree with a basket of snacks
[V] chipmunk riding a toy car down a grassy hill
[V] chipmunk playing with a ball.
[V] chipmunk riding a colorful bicycle through a sunny park.
[V] chipmunk skiing down a slope
[V] chipmunk zooming on a hoverboard

[V] pig swinging on a tire swing in a backyard playground
[V] pig pretending to fly with a cape in the wind
[V] pig skiing down a slope
[V] pig dancing in a field filled with colorful flowers
[V] pig surfing on a big tall wave
[V] pig jumping happily in a pile of autumn leaves.
[V] pig driving a race car
[V] pig walking to school with a backpack and a hat on his head

[V] boy in a field
[V] boy exploring an underwater world
[V] boy building a sandcastle on the beach
[V] boy splashing in puddles
[V] boy in a field of flowers
[V] boy blowing bubbles
[V] boy riding a race cart
[V] boy on a camping trip

[V] porcupine swinging on a tire swing in a backyard playground
[V] porcupine walking to school with a backpack and a hat on his head
[V] porcupine riding a toy car down a grassy hill
[V] porcupine surfing on a big tall wave
[V] porcupine racing toy boats in a bathtub filled with water.
[V] porcupine building a sandcastle on a sunny beach.
[V] porcupine skateboarding down a gentle slope with excitement
[V] porcupine dressing up in different hats and accessories

[V] cat running through fallen leaves in an autumn forest
[V] cat happily cuddled in a comfy blue blanket
[V] cat splashing in a puddle after rain
[V] cat rollerblading in the park
[V] cat running through a meadow
[V] cat on a scooter
[V] cat wearing a fancy hat, looking adorable.
[V] cat lounging in a hammock.

[V] woman walking down the street with a backpack
[V] woman lounging on a hammock with closed eyes
[V] woman reading a book
[V] woman in a field of flowers
[V] woman creating an artistic masterpiece in a sunlit art studio
[V] woman enjoying morning coffee at a cozy cafe
[V] woman playing with a cute dog
[V] woman riding her bike

[V] dog driving a race car
[V] dog sailing in a miniature boat
[V] dog dressed as a chef cooking in the kitchen
[V] dog flying in the sky
[V] dog wearing sunglasses, looking cool
[V] dog riding a skateboard
[V] dog rollerblading in the park
[V] dog playing with a helicopter toy