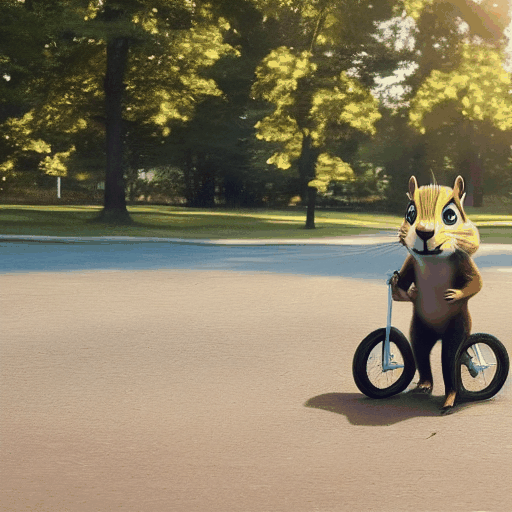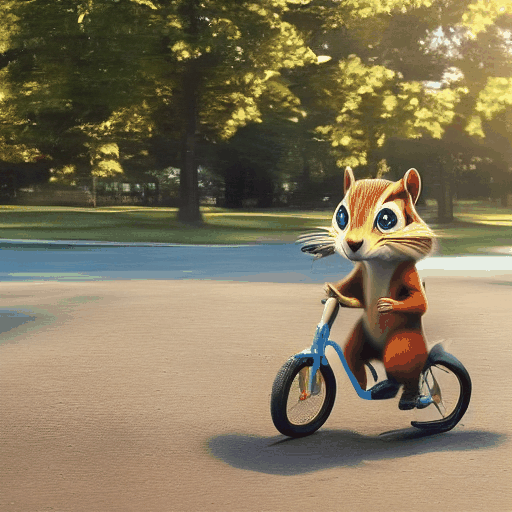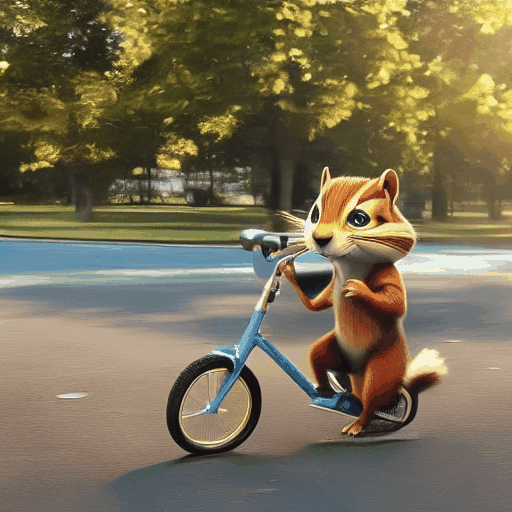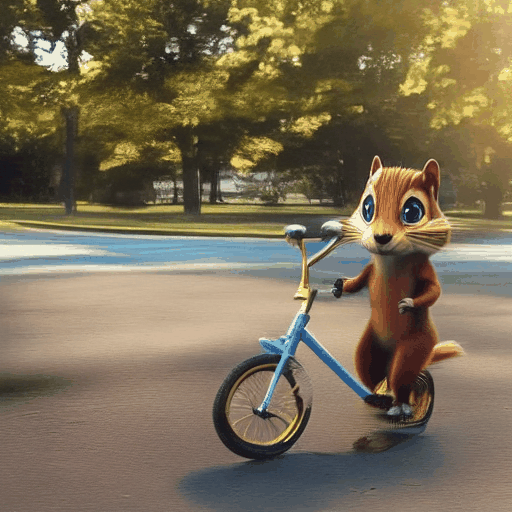AnimateDiff Results
We demonstrate the robustness of our method by showing the results of applying Still-Moving to the AnimateDiff T2V model (see Sec. 4.1 and Appendix). We compare our method with naive injection suggested by AnimateDiff [Guo et al. 2003], using the same seeds and prompts.
As can be observed, the naive injection approach often fails short of adhering to the customized data, or leads to significant artifacts. For example, the "melting golden" style (top rows) displays a distorted background and lacks the melting drops that are characteristic to the style. The featurs of the chipmunk (bottom rows) are not captured accurately (e.g., the chicks and the forehead’s color). Additionally, the identity of the chipmunk changes across the frames. In contrast, when applying our method, the “melting golden” background matches the reference image and the model produces dripping motion. Similarly, the chipmunk maintains a consistent identity that matches the reference images.